Towards LLM-Powered Ambient Sensor Based Multi-Person Human Activity Recognition
ICPADS 2024 - The 30th International Conference on Parallel and Distributed Systems

I am full Professor in Computer Science at University Grenoble Alpes and researcher in the LIG laboratory
My current research interests are about multimodal perception and behavior analysis, mainly of humans, in the context of smart spaces/ubiquitous computing, healthcare and assistive technologies and/or affective computing. These researches could be applied to sociable robot companions, autonomous cars, smart homes or any human/agent interactions.
Research topics:
• Multimodal perception for interaction
• Smart spaces/Ambient assisted living
• Affective computing
• Sociable interaction with robots and autonomous cars
Machine Learning (including Deep Learning) with several sensors (microphones, cameras, RGB-D, LIDAR, ...) for perception of Humans.
This research addresses the use of multimodal sensors (microphones, cameras, RGB-D, LIDAR, ...) to perceive humans, their behaviors and mental states. This researc spans from low level signal processing up to high level machine learning. Deep Learning is now included as machine learning technique for its performance on some of our perception tasks.
Keywords:
• Machine Learning
• Deep Learning
• Computer vision
• Multimodal processing
• Sociable robot
Use perception of humans and sociable feedback from the system in the interaction loop.
In the first part of the interaction loop, we use perception of humans as input for intelligent systems (robot companions, social robots, autonomous cars...). This information permits to anticipate human needs or to predict human behaviors. The second part of the interaction loop, feedback from the system is studied. For instance, in the case of a social companion, its animation must reflect its internal state and must be directly readable/understandable by its human partner(s). For mobile devices, mobile robots or autonomous cars, their navigation must be sociably acceptable and predictable.
Perception within smart spaces from two points of view.
On this research topic, two points of view are addressed. The first one is how to distribute perception systems in smart spaces or in ubiquitous environments. Our reflection leads to Omiscid, a middleware for distributed (perception) systems in such environment. The second point of view inquiries usage of perception researches to help people in their daily life at home (notably elderly) or at work. We also study usage of IoT objects to complete human perception/system feedback in smart spaces or smart homes.
List of research projects, software and datasets contributions
Since 1998, I have been involved in many research projects. I also initiated some personal projects on some specific topics like in the MobileRGBD project.
Current projects:
CEEGE, VALET, MobileRGBD, Expressive Figurines, Equipex Amiqual
Former projects:
Pramad, PAL, ICT Labs, CASPER, CHIL, FAME, NESPOLE!, C-STAR II
Contributions.
You can take a look at my GitHub page, toMobileRGBD, a publication on BRAF-100 French corpus.
ICPADS 2024 - The 30th International Conference on Parallel and Distributed Systems
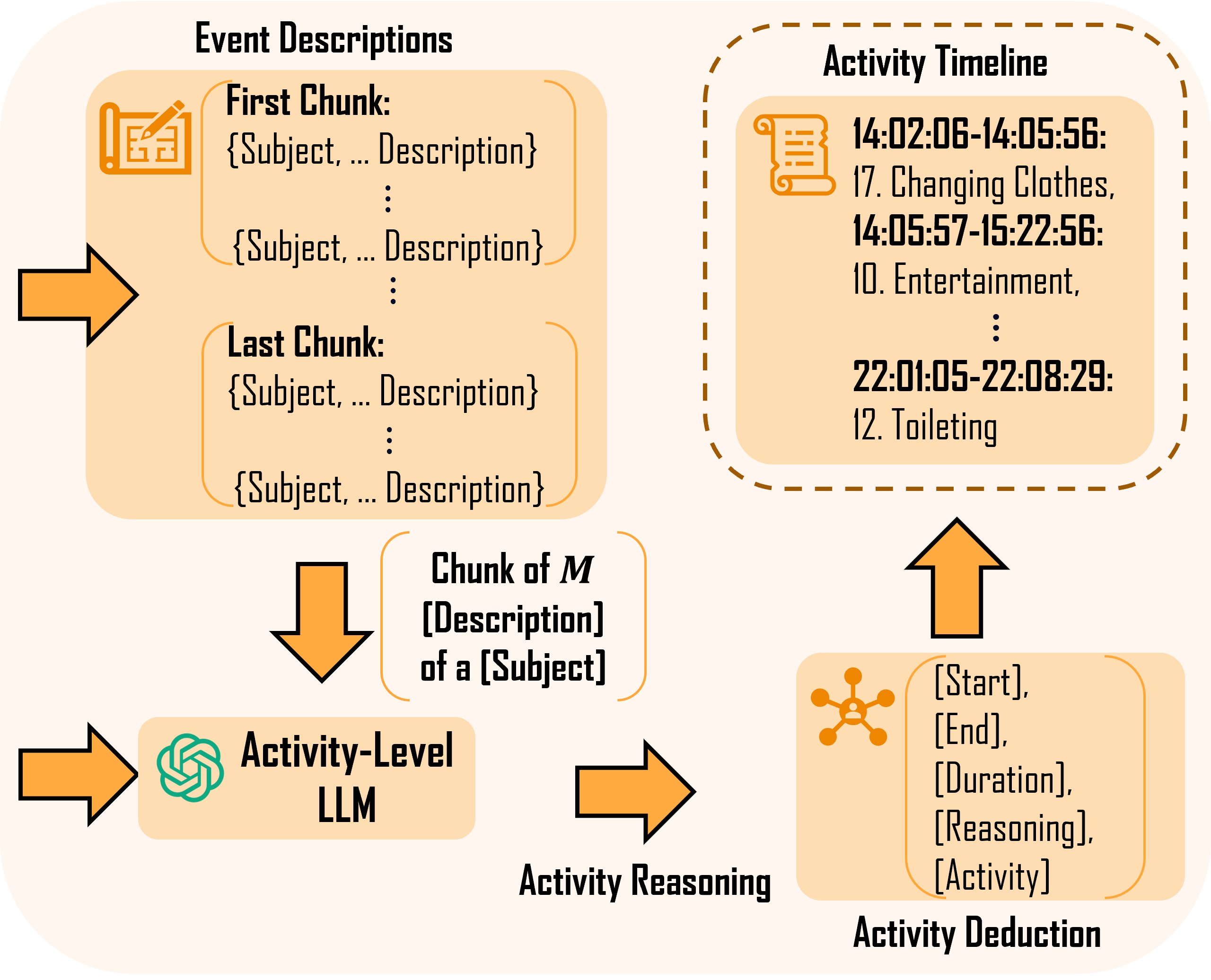
Human Activity Recognition (HAR) is one of the central problems in fields such as healthcare, elderly care, and security at home. However, traditional HAR approaches face challenges including data scarcity, difficulties in model generalization, and the complexity of recognizing activities in multi-person scenarios. This paper proposes a system framework called LAHAR, based on large language models. Utilizing prompt engineering techniques, LAHAR addresses HAR in multi-person scenarios by enabling subject separation and action-level descriptions of events occurring in the environment. We validated our approach on the ARAS dataset, and the results demonstrate that LAHAR achieves comparable accuracy to the state-of-the-art method at higher resolutions and maintains robustness in multi-person scenarios.
ACM Transactions on Multimedia Computing, Communications and Applications (2024)
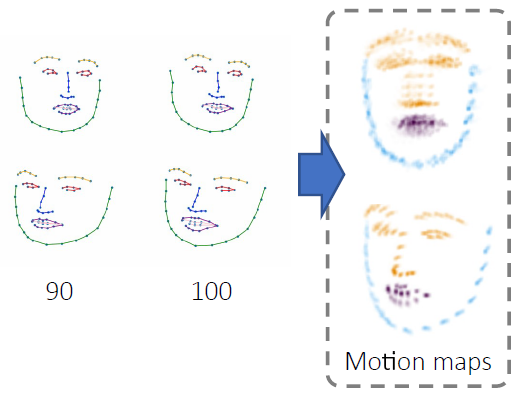
In this work, we address the task of unconditional head motion generation to animate still human faces in a low-dimensional semantic space from a single reference pose. Different from traditional audio-conditioned talking head generation that seldom puts emphasis on realistic head motions, we devise a GAN-based architecture that learns to synthesize rich head motion sequences over long duration while maintaining low error accumulation levels. In particular, the autoregressive generation of incremental outputs ensures smooth trajectories, while a multi-scale discriminator on input pairs drives generation toward better handling of high- and low-frequency signals and less mode collapse. We experimentally demonstrate the relevance of the proposed method and show its superiority compared to models that attained state-of-the-art performances on similar tasks.
CVPR2022 - IEEE/CVF Computer Vision and Pattern Recognition Conference
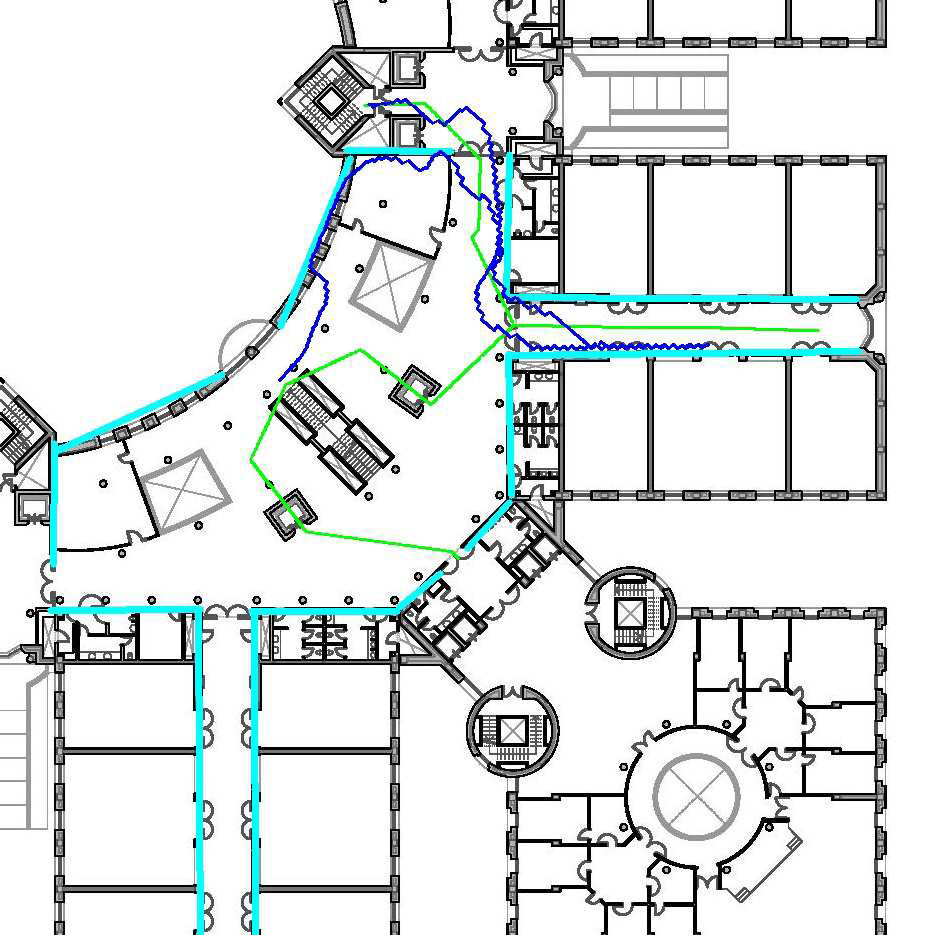
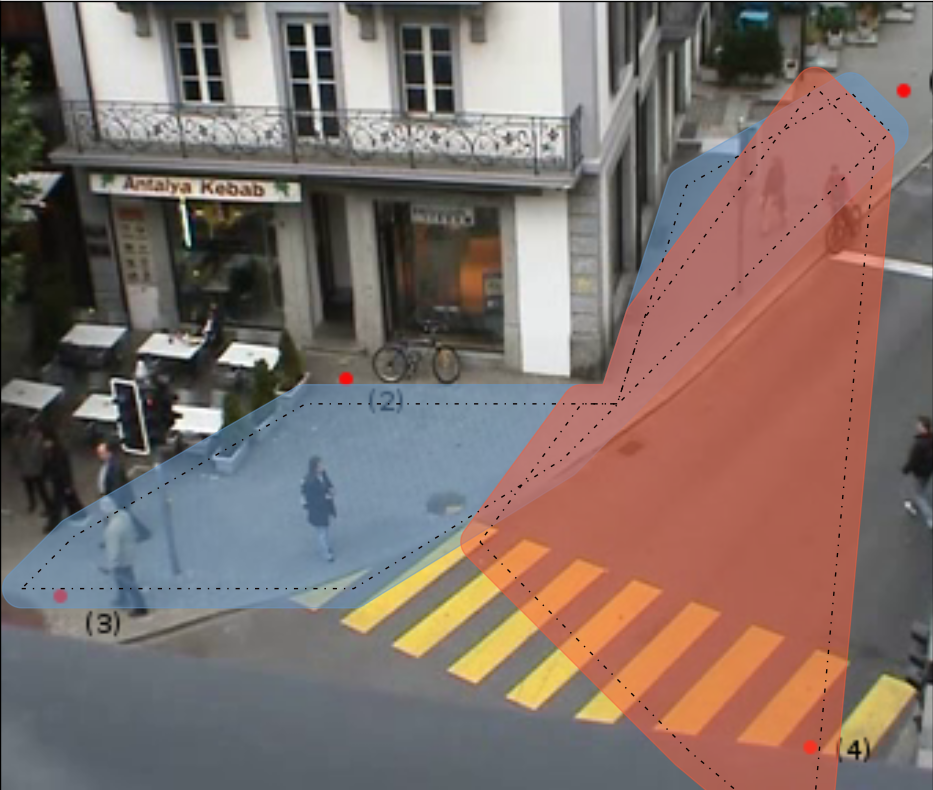
Transformers trained with self-supervision using self-distillation loss (DINO) have been shown to produce attention maps that highlight salient foreground objects. In this paper, we show a graph-based method that uses the self-supervised transformer features to discover an object from an image. Visual tokens are viewed as nodes in a weighted graph with edges representing a connectivity score based on the similarity of tokens. Foreground objects can then be segmented using a normalized graph-cut to group self-similar regions. We solve the graph-cut problem using spectral clustering with generalized eigen-decomposition and show that the second smallest eigenvector provides a cutting solution since its absolute value indicates the likelihood that a token belongs to a foreground object. Despite its simplicity, this approach significantly boosts the performance of unsupervised object discovery: we improve over the recent state-of-the-art LOST by a margin of 6.9%, 8.1%, and 8.1% respectively on the VOC07, VOC12, and COCO20K. The performance can be further improved by adding a second stage class-agnostic detector (CAD). Our proposed method can be easily extended to unsupervised saliency detection and weakly supervised object detection. For unsupervised saliency detection, we improve IoU for 4.9%, 5.2%, 12.9% on ECSSD, DUTS, DUTOMRON respectively compared to state-of-the-art. For weakly supervised object detection, we achieve competitive performance on CUB and ImageNet. Our code is available at: https://www.m-psi.fr/Papers/TokenCut2022/
Modeling Cognitive Processes from Multimodal Data (MCPMD) Workshop at 20th ACM International Conference on Multimodal Interaction (ICMI2018), Oct 2018, Boulder, Colorado, United States.
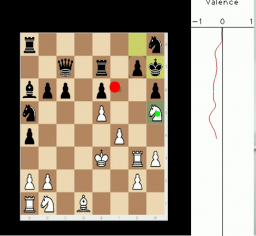
In this paper we present results from recent experiments that suggest that chess players associate emotions to game situations and reactively use these associations to guide search for planning and problem solving. We describe the design of an instrument for capturing and interpreting multimodal signals of humans engaged in solving challenging problems. We review results from a pilot experiment with human experts engaged in solving challenging problems in Chess that revealed an unexpected observation of rapid changes in emotion as players attempt to solve challenging problems. We propose a cognitive model that describes the process by which subjects select chess chunks for use in interpretation of the game situation and describe initial results from a second experiment designed to test this model.
I am full Professor in Computer Science at University Grenoble Alpes and in the LIG laboratory .
I am currently leading the Multimodal Perception and Sociable Interaction (M-PSI) team at the LIG laboratory .
From 2005 to 2023, I was Maître de Conférences (Associate Professor, HDR in 2018) in Computer Science at Grenoble Alpes University and in the LIG laboratory .
In the 2000s, I was involved in the European projects FAME and CHIL for integration of the context (linguistic, thematic, situation awareness) in the acoustic perception (speech recognition, speaker's localization) within an intelligent environment. I also worked on an intelligent virtual cameraman. Later, I started to work on multimodal perception and social interaction, notably in the context of Ambiant Assisted Living (AAL) and social robotics. On these research topics, I participated in the CASPER, PRAMAD, PAL, Valet and CEEGE projects. The PRIMA and Pervasive Interaction teams were part of Inria and GRAVIR/LIG laboratories.
My Ph.D. thesis was about "statistical language modeling using Internet documents for continuous speech recognition". My contributions on French speech recognition were used within the CStar and the Nespole! international projects.
Image courtesy of JP Guilbaud.

CS 40700
38058 Grenoble cedex 9 - France
+33457421625 Dominique.Vaufreydaz@imag.frBATEG
BP 47
38040 Grenoble cedex 9. France
+33476827836 Dominique.Vaufreydaz@univ-grenoble-alpes.fr